
ClickHouse vs StarRocks vs Presto vs Trino vs Apache Spark™ — Comparing Analytics Engines
.png)
Introduction
The analytics landscape is moving at breakneck speed. Each year, the choices for analytics tools available on the market seem to be ever-expanding. This is merely tracking the demand for generating insights from data, which is also growing at lightning speed. For example, during the late 1990s, when the data warehouse model was state-of-the-art, Walmart had 19TB of customer data stored across all its data warehouses. Today, Walmart analyzes 2.5 PB per hour.
As the volume of data grew, engineers needed to scale analytics from the database or data warehouse and onto a scalable dedicated engine. Analytics engines such as Apache Spark, PrestoDB, Trino, StarRocks, and ClickHouse offered engineers the ability to use a cluster-based compute approach to perform OLAP operations.
At Onehouse, we have had the opportunity to not only witness the exciting capabilities of many of these tools hands-on with our customers, but also shoulder the responsibility of recommending which tool is the best for solving their problems. It becomes immediately clear that there isn’t a one-size-fits-all approach regarding the best engine for analytics use cases.
In this blog, we will dive into the architecture and tradeoffs of five of the distributed analytics engines on the market. Through this analysis, we hope that you can come away with clarity on which engines may be a better first choice for the challenges that you are facing in your organization.
What is a distributed analytics engine
An analytics engine is a powerful server software system designed to query and analyze large-scale datasets, typically using SQL. Some also provide users with the ability to federate queries across specialized data storage systems, leveraging integrated data catalogs and optimized compute resources to execute these queries efficiently. This enables organizations to extract insights from their data and supports use cases such as dashboards, ad hoc analysis, real-time lookups, and derived tables. In essence, it serves as the key interface through which analysts and decision-makers access and utilize data to drive informed decisions.
Distributed engines use a coordinator-worker architecture to plan and distribute workloads across multiple machines (nodes). These nodes then perform parallel operations (or tasks) based on scheduling orchestrated by the master. This architecture can vary based on the engine, but we’ll look at a generic design blueprint first before diving into how each engine handles different query types.

Source: https://www.researchgate.net/figure/Architecture-of-the-query-engine_fig1_281352590
As can be seen above, analytics engines execute queries using the following steps:
- Parsing – The SQL query is parsed into a syntax tree to validate structure and identify tables involved.
- Planning – The master generates a logical plan to describe what operations are needed (e.g. filters, joins) and the order in which to execute them.
- Optimization – The logical plan is transformed into an efficient physical plan using cost-based or rule-based optimizations.
- Compilation – The physical plan is compiled into lower-level operations or bytecode or hardware-specific instructions, ready for execution
- Execution – The plan is distributed to workers with intermediate data/metadata returned to the master. Workers execute the plan, in parallel, by scanning data, applying transformations and exchanging data.
- Result Serving – The final result is collected, formatted, and returned to the user or downstream system.
Engine categorization
The engines in our comparison can roughly be defined into three distinct categories based on their primary use cases and architectural design: General Purpose Engines, Interactive SQL Engines, and Realtime OLAP Engines. General Purpose Engines are versatile systems designed to handle a wide range of workloads, from batch processing to complex analytical queries, making them suitable for diverse data applications. Interactive SQL Engines, on the other hand, are optimized for ad-hoc querying and fast response times, enabling data analysts and engineers to explore and interact with data in a more responsive, iterative manner. Lastly, Realtime OLAP Engines are purpose-built for high-speed analytics on constantly changing data, offering sub-second query performance and low-latency insights for use cases that demand near-instantaneous decision-making. Grouping the engines this way will help add clarity to their strengths and trade-offs as we continue through the blog.

General Purpose Engines
Apache Spark was invented in 2009 at UC Berkeley’s AMPLab. It is a general purpose, cluster-based compute engine originally designed to overcome the limitations of Hadoop Map-Reduce ecosystems. The Spark architecture is illustrated below. The Spark driver process is the central coordinator of Spark applications. It manages CPU and memory usage, broadcasts variables (to efficiently share data across workers), and creates Resilient Distributed Datasets (or RDDs, which are Spark’s fundamental data structure).

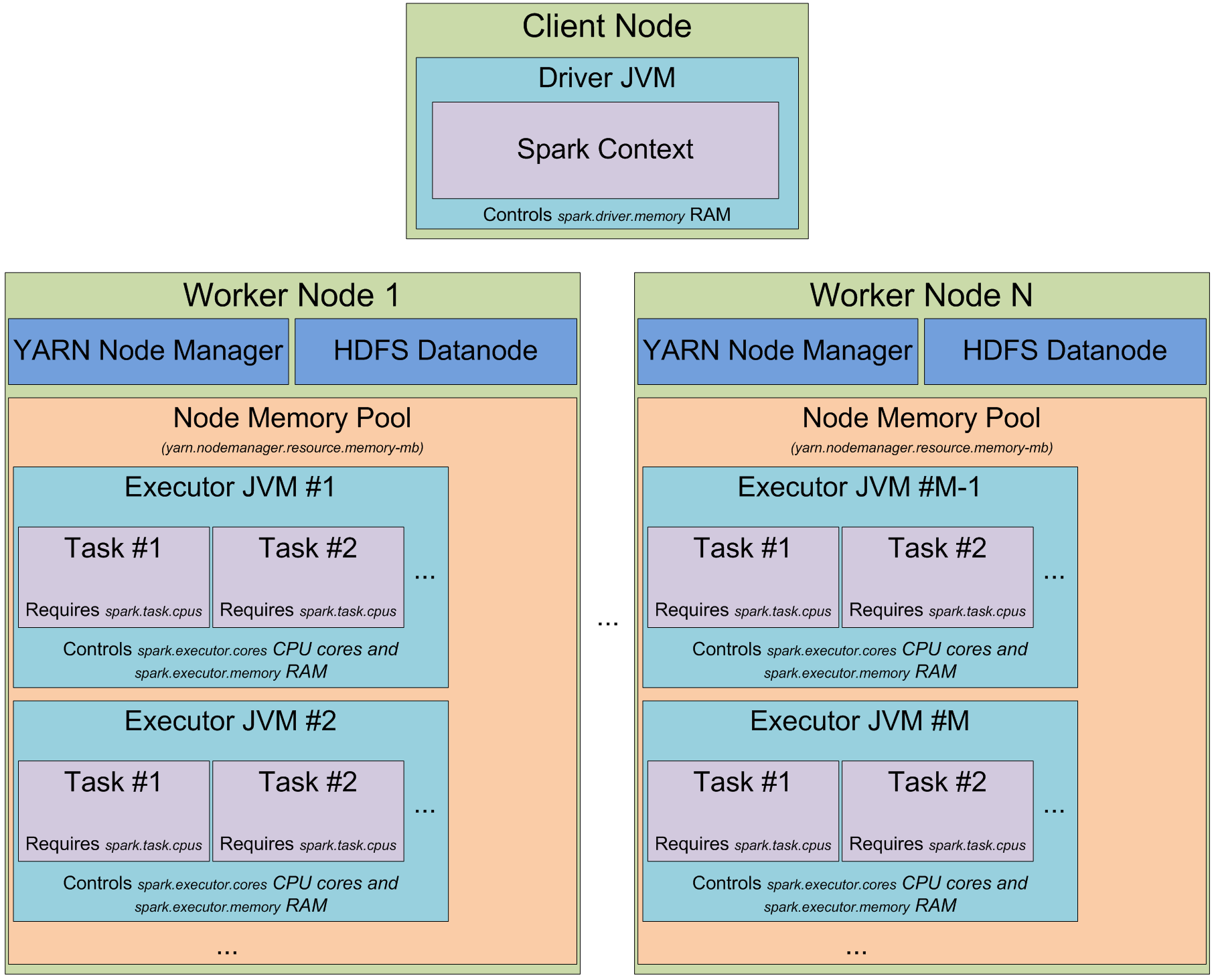{kind=link}
Spark’s distributed, resilient architecture makes it an excellent general purpose engine, where it provides a foundation for a variety of workloads, including but not limited to SQL queries, streaming, ML training/support, ETL, and more.
Interactive SQL Engines
PrestoDB was originally created at Facebook (Meta) in 2012. It was created to provide fast, distributed SQL capabilities across a wide variety of data sources — including HDFS, S3, MySQL, and Cassandra — without the need to move or transform the data. Trino was later created in 2019 as a fork of the Presto project by its original creators, touting focus on performance improvements and added support for cloud and modern lakehouse architectures. As will be apparent through the course of the blog, these engines are still very similar and have only differed in small nuanced ways since the fork.
Illustrated below is the Presto/Trino architecture. In Presto and Trino, the coordinator node parses and plans the query and then creates a series of tasks along with splits (slices of the underlying external storage system), which are each passed to the workers to read the relevant data.

Even though Presto/Trino support a wide variety of connectors, analytics is a key use case for users to adopt these two engines. It’s important to note that these two engines adopt a “shared data” architecture, where the engine workers are stateless and don’t store any local data. All data typically sits as files stored on distributed file systems/cloud storage systems, accessible remotely by the engine workers.
Realtime OLAP Engines
StarRocks was launched in 2020 by engineers from Baidu and other major Chinese tech companies to help enable real-time analytics on modern data lake and data warehouse deployments. The goal was to build a high-performance, massively parallel SQL engine that could support real-time, multidimensional analytics with high concurrency and low latency — especially for scenarios like dashboards, user-facing analytics, and operational intelligence.
StarRocks’ architecture allows for two different models, shared nothing and shared data. In a shared-nothing model, data is loaded into StarRocks format and stored directly in local storage on StarRocks backend nodes. The shared data model enables querying an external data source directly, without copying the data into the StarRocks cluster, similar to Presto/Trino/Spark.

The StarRocks architecture leverages two types of nodes - Frontend (FE) and Backend (BE)/Compute (CN). FE nodes are responsible for metadata management and constructing execution plans. BE nodes execute query plans and store data, using local storage to accelerate queries and the multi-replica mechanism to ensure high data availability. In shared data deployments, compute nodes (CNs) are used instead of BE nodes and serve the same functionality as BE nodes, just without storing data.
ClickHouse was developed in 2009 and launched as open-source in 2016 by engineers at Yandex, Russia’s largest search engine. It was originally built to power Yandex.Metrica, a high-traffic web analytics platform that needed to process billions of events per day with low latency. Existing databases couldn’t meet the demands of real-time, high-concurrency analytical queries at that scale, especially with complex filtering, aggregations, and joins. ClickHouse was launched as a fast OLAP database to tackle these challenges.
ClickHouse’s architecture uses columnar-based storage, where each operation executes on vectors (chunks of columns), all stored inside the Clickhouse DB on replicated shards. This allows for fast execution of queries with fault tolerant and resilient data. Additionally, ClickHouse allows querying data in cloud storage, similar to external tables in traditional data warehouses.

Query Types
Now that you have a rough understanding about the fundamentals of each engine, you might be wondering, well which one is going to be best for me? The answer heavily depends on your workload patterns and query types. In this next section we will quickly review the broad categories of query types that have importance for analytics.
Scans
In analytical engines, scan operations are the foundational physical operators responsible for reading raw data from storage. While seemingly simple, getting scans right is critical to overall job performance, as they often dominate I/O and CPU costs in data-intensive workloads.
Analytics engines typically leverage columnar storage formats such as Parquet and ORC to read only the specific columns required by a query. These formats support predicate pushdowns, where filters are applied as early as possible, minimizing the volume of data loaded into memory. Pushdown works by evaluating filter predicates using lightweight metadata such as min/max statistics, Bloom filters, or dictionary-encoded page headers, allowing entire row groups or pages to be skipped without deserialization.
When reading from files on disk or cloud object stores, scan performance is heavily influenced by I/O parallelism and data layout. Systems such as Presto, Trino, and Spark use coordinated scan scheduling to assign file splits across worker threads or nodes, optimizing for locality and parallel throughput. Even with modern SSDs and fast cloud object storage, raw data throughput can become a limiting factor.
Common Optimizations
Listed below are a few common optimization techniques that engines can use to speed up scan queries:
- Query Plan Optimizers use table/engine metrics, predefined rules, or a series of heuristics to adjust the query plan such that it minimizes the amount of compute and execution time required.

- Dynamic Filtering or Partition Pruning allows engines to identify when source or incremental data is not relevant to the query and will automatically prune that data from the scan operation.
- Data Parallelization allows for reading and processing different parts of the source dataset simultaneously, speeding up the scan operation
Joins
Joins are another common operation that you are certain to encounter as you execute queries on your tables. Joins refer to combining data from two or more tables by matching values on a “join predicate”. Join predicates are combinations of keys that are matched together from one table to another to match records from the two tables. Users may often have to use data from many tables to create the insight that they need. For example, a query may need to retrieve sales results across countries, where each country’s data is stored in a different set of tables. Efficient joins make these queries possible.
Example Join Query
SELECT
customers.customer_id,
customers.name,
orders.order_id,
orders.order_date,
orders.total_amount
FROM customers
INNER JOIN orders ON customers.customer_id = orders.customer_id
WHERE orders.order_date >= '2024-01-01'
ORDER BY orders.order_date DESC;General Algorithm for Join Execution:
- Determine which join (inner, left, right, etc.) is employed and what the source and merged data will be.
- Distribute partitions of the data to the worker nodes.
- Map data from the two datasets together within each partition (as sent to the worker nodes).
- Collect the results back together from all the workers and report back to the user.
Join Strategies:
In distributed engines, there are a few different join strategies that engines can employ depending on the characteristics of the data that is being joined. Each of these join strategies has advantages that come to light and must be used when the data profile matches.
- Broadcast Join: When joining a small table (<10 MB) to a large one, the small table is loaded in memory and sent to each executor. Here, the executor can use the table in memory to match against the larger table, speeding up the join process. Good for datasets where 1 (or more) tables are small and can be held in memory.
- Shuffle Join: Both datasets are shuffled to executors across the join key, such that matching rows are co-located on the same executor node. Good for large datasets that don’t fit in memory with evenly distributed join keys.
- Hash Join: One of the tables is loaded as a hash table, and the other table is iterated over matching values in the hash table to create the join.
- Dynamic Partition Join: The engine identifies the valid partitions from the tables that are relevant to the join query and only applies those partitions to the query. This decreases the number of tasks that are needed to process the query.
- Sort Merge Join: When the tables are already sorted (or can be sorted efficiently), this strategy uses the sorted datasets and matches the keys in order (with sorting making this process easier).
Query Plan Optimizers:
Just like in Scan operations, query plan optimizers can identify and optimize the best order of operations to execute the query such that the execution time and compute cost are minimized.
Aggregations
Aggregations are operations that are a part of nearly all analytical queries. These operations include SUM, COUNT, AVERAGE, MIN, MAX, GROUPs, and more. These operations can appear in both ad-hoc queries and regularly running queries that are submitted to the engines. For example, a dashboard might request rollups of several metrics that are highly granular and span many TBs of files. In these scenarios, having performant aggregation operations becomes critical to ensuring the query executes according to the business need.
At a high level, aggregation functions can be stateless or stateful. Stateless aggregates, such as MIN or MAX, require no memory beyond the current best value and can be updated incrementally with each incoming row. In contrast, stateful aggregates such as AVG, STDDEV, or PERCENTILE maintain running totals or intermediate states and may require multiple passes or complex state tracking to produce final results.
The two dominant forms of aggregation are global aggregation (aggregating over the entire dataset) and grouped aggregation, typically expressed with GROUP BY. Global aggregation is conceptually simple and often highly parallelizable, but grouped aggregation presents more complexity, particularly when dealing with high-cardinality keys.
To execute grouped aggregations, engines generally employ one of two algorithms: hash-based aggregation or sort-based aggregation. Hash-based aggregation constructs an in-memory hash table where each group key maps to an accumulator structure. This method is efficient for unsorted, uniformly distributed data and can support streaming input. However, when memory is constrained or the key distribution is skewed, hash tables can overflow or become performance bottlenecks. Alternatively, sort-based aggregation first sorts input rows by the group keys, enabling aggregation via sequential scans over sorted runs. This approach is more predictable in memory usage and is especially beneficial when data is already sorted or partially ordered on disk or during shuffle stages.
Example Aggregation Queries
SELECT region, SUM(revenue) AS total_revenue
FROM sales_data
GROUP BY region;Windows
A window query lets you perform calculations across rows related to the current row. These queries are important in executing calculations on a dataset without collapsing it. Executing window operations can allow analysts to generate additional insight which may not be immediately clear from the metrics in the table. For example, they can use a window function to rank items, or create running totals - creating insight that wasn’t previously present.
Sample Window Query
SELECT
user_id,
purchase_date,
amount,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY purchase_date) AS purchase_order
FROM purchases;
# Creates an order for each user's purchases by date
As shown in the sample query above, you will see the window operation defined as an OVER() clause. This tells the query which rows to include in the “window” for the calculation. Within the OVER clause is a specification of a PARTITION BY and an ORDER BY statement. When the ORDER BY clause defines a strict global order it becomes difficult to parallelize and the cost can grow large.
High-Level Process:
- The engine evaluates the partition attributes and each partition is evaluated independently
- Within each partition, rows are ordered by the order by clauses
- The sliding window frame gets the subset of rows for calculation (this is sped up via pointer math rather than a scan)
- Results are computed for the function and reported
Now, this is not every operation that these engines can execute or support. Just glancing at the Trino docs shows dozens of operations we haven’t discussed. But, keeping these query types in mind, we can now move to look at the feature differentiations between each of these engines.
Feature Comparisons
Based on what we have discussed so far, you may be asking yourself, “Why are there so many engines in the market?” After all, it's just the same SQL executing across all these engines. The devil is in the implementation details and how these different engines make various tradeoffs on SQL execution. In this next section, we will dive deep into a head-to-head comparison of the engines, evaluating them across various aspects of engine design, scalability, concurrency, storage support, query languages, and their place in the broader ecosystem.
In each section I assign a grade for how well the engine compares based on the attribute being measured: A = best solution; B = good solution, and; C = below average. After the 1-by-1 analysis I also created a metascore where I awarded 3pts for every A, 2 for a B, 1 for a C. The metascore is a normalized sum of all points across all features and categories. Below are the rankings from the metascore:
.png)
The purpose of this blog is not to declare a single winner or loser amongst the engines, but provide a base of research that you can use to inform your own decision making. It is important to note that this compiled metascore is not a perfect scientifically measured score. For example, perhaps not all features should be given equal weights. Is it possible to create an objectively perfect score? I don’t think so… So take my analysis as a starting point to do your own research. A few of the ratings below could be interpreted as subjective, if you disagree with a rating, reach out to me and I would love to learn from your perspective and perhaps adapt my conclusions.
Engine Design
When it comes to analytics engine design, all roads typically lead to how users can get the fastest response times for their queries. This contrasts against general-purpose engines like Spark, which also tend to optimize for throughput (over latency) and resiliency to failures (restarting large ETL jobs can be resource-intensive). To this end, we find that engines with the best-in-class SIMD support and advanced caching offer much better query performance compared to general-purpose Spark or JVM engines, which are still moving closer to this model.
🏆 Best in class: ClickHouse, StarRocks
❌ Worst in class: Apache Spark
|
|
Vectorized columnar processing
(Does the engine optimize for processing columnar data?) |
Shuffle speed and efficiency
(How quickly can the engine exchange data for operations that span workers?) |
Caching of source tables or intermediate data
(Does the engine have cache support for intermediate operations?) |
Query plan optimizers
(Does the engine have support for producing intelligent query plans?) |
|
|
A
ClickHouse has SIMD support to accelerate queries, based on the MonetDB model. ClickHouse is renowned for its blazing fast queries. |
A
ClickHouse’s MPP processing with data sharded across nodes allows for in-memory shuffle. It has different join algorithms and adaptive spilling thresholds to balance scenarios where tables don’t fit in memory.
|
A
ClickHouse has a variety of different caches that can be leveraged to cache data and even different indexes. ClickHouse has a result cache that can reduce need for re-execution for identical queries (e.g., a popular dashboard loaded by many users) |
A
ClickHouse has a rules-based optimizer and has a config to autoselect join strategies. It compensates for lack of cost-based optimizer through nifty data-skipping and indexing techniques. |

StarRocks |
A
StarRocks is implemented in C++ which allows for full SIMD support across relevant operations |
A StarRocks MPP model means stages are executed in parallel and data is shuffled across nodes in-memory. This speeds up queries but can require higher memory usage. |
A StarRocks automatically enables data caching and can also cache intermediate query results, which significantly speeds up query response times. |
A StarRocks has a cost-based optimizer to adjust join strategies and query ordering. |

PrestoDB |
C Limited SIMD support due to Java runtime limitations. However, the Velox execution engine written in C++ brings native SIMD support, through the Prestissimo project. Not turned on by default. |
A PrestoDB also uses an in memory buffered shuffle to exchange intermediate task results without persisting to disk, speeding up query performance. Newer versions of Presto allow for spilling to disk, via the exchange materialization support. |
B Presto can support caching data and metadata at filesystem level using Alluxio. |
A Presto has a built-in cost-based and rules/heuristic based optimizer to adjust query plan ordering, join strategies, and more to accelerate query performance |

Trino |
C
Limited SIMD support due to the Java runtime limitations. Trino plans to use Java vector APIs to achieve this. Experimental support for Parquet decoding. |
A
By default, Trino uses an in memory buffered shuffle to exchange intermediate task results speeding up query performance. Recently, added fault-tolerant execution and spill to disk for large queries that don’t fit in cluster memory. |
B
Trino provides automatic support for caching of both filesystem data and metadata, using the OSS Alluxio libraries.
|
A
Trino has a built-in cost-based optimizer that adjusts join orders and picks join strategies based on |

Apache Spark |
B
Spark provides vectorized Parquet/ORC readers. However, it does not support end-end columnar processing out-of-box. Project Tungsten aims to achieve good cache alignment, code generation and better memory management, to unlock SIMD acceleration from underlying hardware. It’s not turned on by default, suggesting that it’s not widely used. |
C
Spark follows a stage driven execution model, where intermediate results from one stage are shuffled via disk to the next stage. This can slow down query execution times but can be very desirable for large ETL/data pipelines.
|
C
Spark supports caching at individual dataframe level, from Spark programs or notebooks. However, the user needs to manually persist/unpersist these dataframes explicitly. It does not have a simple cluster-level automatic caching mechanism. |
B
Spark has adaptive query execution, and catalyst optimizer to adjust plan and perform optimizations such as dynamic pruning of source table scans, based on results of scanning the previous tables in the stage. A built-in cost-based optimizer can help perform join re-ordering, but in many common cases the statistics collection lags behind to support it. |
Scalability
Being able to scale the cluster up or down, as queries start and complete, is an important part of ensuring great query performance and optimizing costs at scale. Shared-data vs shared-nothing plays a key role in the simplicity of scaling these engines. Presto (with years of hardening at planet-scale at Meta) offers the easiest way to operate at scale with its storage/compute separation and high-availability features. StarRocks/Clickhouse with local data storage add expected complexity to cluster scaling, in return for the great performance shown in the previous section. Spark is typically used for running ETL jobs at scale and comes up short again.
🏆 Best in class: Presto
❌ Worst in class: Apache Spark
|
|
Elastic scaling
(How does the engine horizontally scale out or in with workload change?) |
Data parallelism
(How is data processed in parallel?) |
Load balancing
(How easily can the user distribute queries across different clusters when workload demands spike?) |
High availability
(How does the engine handle failure of critical components and minimize query downtimes?) |

ClickHouse (OSS) |
B
Horizontal scaling
is done via manual cluster resizing;
automatic
vertical scaling is available through another
OSS project.
|
A
The input ClickHouse node distributes as much work for the scan to other nodes to execute as possible alongside it |
B
ClickHouse has community provided load balancers such as chproxy. ClickHouse also has an interesting approach, where queries can be redirected to remote clusters. |
A
ClickHouse can be deployed in a highly-available fashion using the right HA deployment architecture. Provides resiliency against failures through replication of data, zone-aware placement of processes and automated failover mechanisms. |
|
StarRocks |
B StarRocks offers scaling APIs for frontend, backend and compute nodes. These APIs can integrate with k8s autoscaler to scale nodes up or down.
Note that stateful servers (i.e., local storage tables) add significant complexity to cluster scaling and elasticity. |
A StarRocks identifies individual query fragments and executes each in parallel across all relevant nodes |
B
StarRocks is MySQL protocol compatible and has ways to load balance across clusters. However, shared-nothing tables need to be present on all clusters, doubling the storage costs. Data lake tables can work without storage duplication. |
A
StarRocks frontend nodes are replicated, and if the current leader node fails another one takes over. Even for shared-nothing tables, with sufficient replication the queries can continue running when backend nodes fail.
|
|
PrestoDB |
A Pushes metrics on CPU/memory usage and engine-specific details to autoscaler, which handles scale up.
Enforces graceful shutdown and cooldown periods when pods are marked for deletion to ensure queries continue.
Integrates with YARN or Kubernetes to manage nodes. |
A Data is divided into splits (sections of the larger dataset), which are each handled in parallel by different worker tasks |
A It’s possible to similarly balance workloads across nodes. In addition, there are external load balancers that can be leveraged. |
A Presto supports disaggregated coordinators to share a set of workers across multiple coordinators, which means the cluster on whole is resilient to both worker and coordinator failures.
|
|
Trino |
A Uses external autoscalers and cluster managers to provision/deprovision nodes based on CPU and memory utilization on the Trino cluster. Integrates with K8s to manage nodes and autoscaling as well
|
A Data is divided into splits (sections of the larger dataset), which are each handled in parallel by different worker tasks. |
A Trino allows for balancing workloads across clustering using the Trino Gateway. In addition, external load balancers are available to support advanced load balancing. |
B Trino coordinator is a single point of failure. Users that desire high-availability should deploy multiple clusters with load balancing, which can increase operational overhead for simple deployments. The silver lining is that the workers simply become idle and need not necessarily be restarted.
|
|
Apache Spark |
A Spark has a Dynamic Resource Allocation component, which scales executors up/down based on demand
Cluster managers (self-configured) provision or deprovision nodes on the fly. Example: YARN, Mesos, Kubernetes, or standalone. |
A Data is parallelized across executors, by compiling SQL down to a DAG of DataFrame transformations. DataFrame is a lazily computed, distributed data structure, which is then computed by running tasks on each dataframe partition across executors. |
B Load balancing is not straightforward since it requires a complex setup of thrift load balancers using tools like NGINX or envoy. |
C Spark driver is a single point of failure within the cluster. Queries will fail until the Spark driver is restarted by a resource manager such k8s, which spins up a new set of executors, which can lead to significant downtime during failures. |
Concurrency
In steady state, these engines need to handle a lot of queries from users and be able to efficiently process them without letting queries step on each other or creating odd side effects. This boils down to concurrently reading/writing data while prioritizing queries based on the user's needs. That way, the queries that are important are not held up by less important queries.
We find that ClickHouse offers the most granular, flexible control over how queries execute. When it comes to transactional support, most engines are adequate for OLAP queries and will fall short when directly compared to typical OLTP/online databases that are used to build end applications.
🏆 Best in class: ClickHouse
❌ Worst in class: Apache Spark
|
|
Concurrent reads
(How does the engine handle simultaneous queries?) |
Concurrent writes (How does the engine handle concurrent writes?) |
Workload priority management
(Does the engine have mechanisms to give priorities to different queries or workloads?) |
|
ClickHouse (OSS) |
A ClickHouse uses dedicated thread pools to prevent workload from blocking. Queries can be labeled as workload, scheduled flexibly using SQL against resources. |
A ClickHouse provides native ACID capabilities with caveats, but adequate for OLAP (if not OLTP workloads) |
A ClickHouse allows very flexible mapping of resources and workloads than the hierarchical queues described above. Allows for modelling individual resources such as disks/cloud storage endpoints with advanced controls/rate throttling based on runtime characteristics of queries such as max_speed, max_burst. |
|
StarRocks |
A StarRocks uses resource groups to manage limits of queries submitted. StarRocks allows finer grained classification of queries based on query type, source IP or even plan cost. |
A Because StarRocks also provides a proprietary storage layer, it can guarantee ACID for each data ingestion operation |
B StarRocks does not support sub-groups within resource groups . Queries are queued once max concurrency is reached. |
|
PrestoDB |
A PrestoDB queries can be submitted to similar resource groups as Trino with granular control for cpu/memory limits. It also lets users enforce a minimum number of workers for each query, to ensure queries run well alongside elastic scaling. |
B PrestoDB does not provide native ACID guarantees but leverages open table formats for ACID compliance. |
A Presto resource groups support similar queueing within each group, to allocate priority. Tasks are executed in fair, weighted, weighted_fair, or priority queue model. |
|
Trino |
A The Trino coordinator schedules queries among resource groups . It also allows for specifying both cpu and memory limits separately. |
B Trino does not provide native ACID guarantees but leverages open table formats for ACID compliance. |
A Queries are executed with different queuing models (fair, weighted, etc.) within each group. It allows even finer-grained sub groups to further isolate/control resources available to queries. |
|
Apache Spark |
A Multiple queries can be submitted from different threads to scheduler pools. The scheduler is thread-safe, allowing setting the scheduler pool for queries from different users. |
B Spark does not provide native ACID guarantees but leverages open table formats for ACID compliance. |
B Queries queue on either FIFO or fair models until resources free up. Scheduler pools can be allocated for priority management. Each pool has a weight and minimum share of resources to be used. Only compute resource control is possible. |
Storage Support
Needless to say, data storage is a very crucial aspect for analytical engines. In this section, we explore different open file, table and storage system support across these engines. The variety of use cases needed to be supported by analytics engines necessitates that engines interact with as broad a range of file formats and storage types as possible.
As more organizations adopt a lakehouse strategy, being able to read and write to many open table formats becomes crucial to making each engine as useful to a broad audience as possible. We find that Spark offers the broadest support, using data sources to read/write Parquet, JSON, ORC, Avro, CSV, and more.

🏆 Best in class: Apache Spark
❌ Worst in class: ClickHouse
|
|
File format support (What file formats are supported?) |
Table format support (What open table formats are supported?) |
Cloud Storage support (Is there support for object-based storage and/or local storage) |
|
ClickHouse (OSS) |
A
Read/write support for Parquet, CSV, TSV, TXT, JSON, ORC and more |
C
|
A
|
|
StarRocks |
A
Read/write support for Parquet, ORC, AVRO, CSV
|
B
Read support for Hudi, Delta, Iceberg, Paimon, Hive
Write support for Iceberg |
A
|
|
PrestoDB |
B
Read/write support for Parquet, ORC . Other file formats are supported through Hive SerDes. |
B
Read support for Hudi, Delta, Iceberg, Hive
|
A
Read/write support for local filesystems, HDFS
|
|
Trino |
B
Read/write support for Parquet, ORC, other file formats are supported only through the Hive SerDes. |
B
Read support for Hudi, Delta, Iceberg, Hive
|
A
Read/write support for local filesystems, HDFS
|
|
Apache Spark |
A
Read/write support for Parquet, JSON, ORC, CSV, text, and more. |
A
Read/write support for Hudi, Delta, Iceberg, Hive, Paimon |
A
Spark can run in local mode and hosted mode and supports writing to S3, HDFS, ADLS, and GCS |
Query Language
SQL support
SQL is the predominant method by which analytics queries are authored and executed. Originating in the 1970s with the first IBM databases, a robust SQL query language enables the analytics engine to be leveraged by technical and business users alike to run analytical queries. All of the engines in our comparison have robust SQL language support for interacting with the data.

Python support
Python has also become the lingua-franca for data engineers and data scientists to interact with data. Offering a robust Python-based experience expands the potential set of use-cases for which an analytics engine can be leveraged. Of the engines in our comparison, Apache Spark offers the best Python experience with its PySpark library. It allows Spark operations and business logic to be defined directly in Python functions. The other engines in our comparison offer client wrappers which still require business logic to be defined in SQL. Spark can seamlessly be used both as a Python library as well as a distributed SQL engine.

🏆 Best in class: Apache Spark
❌ Worst in class: Trino, Presto
|
|
SQL support
(How does the engine support SQL queries?) |
Python support
(How does the engine support programmatic access via Python? ) |
Additional language support
(How are non-python or SQL applications supported?) |
Non-analytics connectors (How can I connect to AI, Data Science or ML platforms and tools) |
|
|
A
SQL-based language to interact with data + system |
B
Python API client for SQL statements |
A
Support for clients in C++, Go, JavaScript, Java, Rust |
B
Clickhouse supports vector search, CatBoost, and using columns as a feature store |
|
StarRocks |
A
SQL-based language to interact with data + system |
B
Python library with support for reading and writing to StarRocks tables |
B
Interface for Java (JDBC), C++ |
B
StarRocks has support for vector indexes and API-based integration with LLMs |
|
PrestoDB |
A
SQL-based language to interact with data + system |
B
Python client wrapper for SQL statements |
B
Clients for Java, JavaScript, Go , Rust |
C
Basic built in ML functions (SVM learn_regressor)
API integration with LLMs and external systems |
|
Trino |
A
SQL-based language to interact with data + system |
B
Python client wrapper for SQL statements |
A
Clients for Java, JavaScript, Go, C# , R (via Presto), Rust (via Presto) |
C
Basic built-in ML functions (SVM classifier, SVM regressor, feature vector).
API integration for LLMs. |
|
Apache Spark |
A
SQL support (Spark SQL) built-in with SQL-like language
|
A
Pyspark for programmatic operations in Python and wrapper for SQL statements |
C
Can write Spark code in Scala, Java, R (using SparkR). |
A
Spark has preinstalled machine learning libraries (MLlib, SparkML, SynapseML).
Spark also has easy integrations to TensorFlow and Pytorch.
Spark’s code based interface allows integration with external APIs. |
Ecosystem
The analytics engine must also interact and integrate strongly with other systems around it. This typically includes data catalogs (open and closed), various deployment frameworks and cloud-native services. Major hyperscalers typically package open-source software for fun and profit.
Although it does not serve as technical validation, it can be helpful to have easy ways to spin these engines up and put them to work.
As evident from our popular blog post, data catalogs come in different shapes and sizes. Wide support across data catalogs prevents technology lock-in on the catalog and engine level. Data catalogs, open table formats (OTFs) and analytics engines need to work hand-in-glove to deliver a magical analytics experience. For example, incorporating OTF metadata or indexes (Hudi) helps the engine generate efficient plans that can dramatically speed up queries.
🏆 Best in class: Apache Spark
❌ Worst in class: ClickHouse
|
|
Catalog support
(What are the data catalogs that are natively supported in each engine? Does it have OTF support) |
Cloud vendor support
(Which cloud vendors have the engine pre-installed?) |
Self-hosted deployments
(How easy is it to deploy the engine in my own environment) |
|
ClickHouse (OSS) |
B
Clickhouse syncs to HMS (for Hive tables) and DataHub.
Clickhouse OSS cannot see catalog metadata for Hudi, Delta, Iceberg |
C
Clickhouse is preinstalled on Alibaba EMR
Notably missing: Amazon EMR, GCP, Azure
Installed on AWS via QuickStart |
B
ClickHouse can be deployed via Docker Image and manually
Third-party tools can help deploy it via Kubernetes |
|
StarRocks |
A
StarRocks syncs to HMS, AWS Glue Catalog, Unity Catalog, and local filesystem.
StarRocks is able to catalog the metadata from Hudi, Iceberg, Delta, and Paimon |
C
StarRocks is pre-installed on Alibaba EMR, and Tencent EMR
Notably missing: AWS, Azure and GCP |
A
StarRocks can be deployed manually and on Kubernetes via Helm and via operator |
|
PrestoDB |
A
PrestoDB syncs to HMS, Glue Catalog, Unity Catalog via the Hive connector, and JDBC based catalog connectors
PrestoDB allows for rich catalog metadata utilization for Iceberg, Hudi (metadata table), and Delta Lake (Delta Standalone Reader) |
B
|
A
Presto supports deployment via Docker, Kubernetes (Helm), and local mode |
|
Trino |
B
Trino syncs to HMS, Glue catalog, Unity Catalog, Oracle Catalog, Nessie, JDBC based catalogs, and more
Trino allows for rich catalog metadata utilization for Iceberg (table stats, projection pushdown, and more) and Delta Lake (metadata, table stats)
|
B
Trino is pre-installed on AWS, GCP, Oracle, and IBM services.
|
A
Trino can be deployed standalone, via Kubernetes, and via a Docker container |
|
Apache Spark |
A
Spark can sync to HMS, Glue Catalog, Unity Catalog, JDBC catalogs, and more
Spark can leverage Iceberg column stats (manually via Glue catalog ), Hudi metadata, and Delta table properties |
A
Spark is pre-installed on AWS, GCP, Azure, Oracle, and IBM cloud services. Additional cloud providers may also support Spark |
A
Spark can support standalone deployment, deployment via Kubernetes, and Yarn and Mesos cluster managers |
Community and Commercial Support
In this section, we present various community metrics that may paint a general picture of how these engines are supported by respective communities or commercial entities championing them.
(⚠️ Data changes rapidly! The table is last 30 days as of 03/17/25)
|
|
Github Momentum (Github stars are an indication of how popular a project is) |
OSS Contributors (# of contributors w/ commits in the last month) |
Contributing Companies (what companies contribute to the project) |
Commercial Offerings (what are the commercial product offerings) |
|
ClickHouse (OSS) |
39.6K |
50 authors |
In order of # of PR creators : ClickHouse (28), Yandex (27), Altinity (10), Tencent (9), and more |
|
|
StarRocks |
9.7K |
36 authors |
In order of # of PR creators : StarRocks (13), Tencent (9), Alibaba (9), and more |
|
|
PrestoDB |
16.3K |
18 authors |
In order of # of PR creators : Facebook (Meta) (77), Starburst (12), Tencent (8), and more
|
|
|
Trino |
11K |
26 authors |
In order of # of PR creators : Starburst (42), AWS (13), LinkedIn (6), Shopify (6), and more |
|
|
Apache Spark |
40.8K |
20 authors |
In order of # of PR creators : Databricks (92), Microsoft (46), Google (29), IBM (26), Tencent(25), and more |
….. and more |
Case Studies
After compiling these in depth feature-by-feature comparisons, one of the main takeaways you can see is that each engine has unique capabilities and will be specialized for different use cases. Regardless of which engine you may choose, organizations from around the globe depend on each of these engines for mission-critical workloads. Listed below are some case studies of the applications that I think are the most exciting:
- [PrestoDB] Powering experimentation and analytics for Data Scientists @ Meta
- [Trino] Powering data platforms @ Goldman Sachs
- [StarRocks] Enabling fast queries on trillions of records @ WeChat
- [Spark] Interactive query platform @ Pinterest
- [ClickHouse] Productionizing AI use-cases @ Weights and Biases
Conclusion
Choosing the ideal engine to solve your concerns isn’t limited to just what you want to accomplish technically. It needs to include future business needs and your strategic direction. Each engine carries with it specific advantages:
- Apache Spark for the broadest ecosystem, storage, and language support. You can connect and operate on nearly any kind of data you need.
- Trino provides a great interactive SQL engine for ad hoc analytics.
- Presto, with its shared history with Trino, also has a great interactive SQL and is hardened to scale efficiently
- StarRocks brings a lightning-fast vectorized engine, but doesn’t have as broad support for file formats and isn’t pre-installed on many platforms.
- ClickHouse also brings lightning-fast vectorization capabilities accelerating OLAP operations, but you may need to rely on ClickHouse Cloud’s offering to deploy and manage your cluster.
No matter which engine you choose, the true power comes from being able to mix and match engines, scale with confidence, and take advantage of ecosystem efficiencies - all without being locked into a single architecture
That’s where Onehouse comes in. At Onehouse, we believe in open data, open engines, and open possibilities. Our platform brings:
- Seamless integration with any analytics engines
- Fast and incremental data ingested directly to your lakehouse storage
- Automatic table management for Hudi, Iceberg, and Delta tables
- One source of truth, regardless of how many engines touch your data

With Onehouse not only do you get fully managed ingestion, incremental ETL, and table optimizations, but now with our newly released Open Engines platform you have the ability to launch clusters with a variety of open source engines at the click of a button:

Ready to tackle your analytics challenges? We would love to chat! Contact Onehouse at gtm@onehouse.ai to get the details behind how we did these comparisons and how you can achieve 2-30x performance gains seamlessly running Spark, Trino, Presto, StarRocks, or ClickHouse.

Read More:

The Onehouse Data Integration Datasheet: Your Guide to Seamless Data Connectivity

Apna Unlocks AI Job Matching for 50 Million Users With Confluent & Onehouse




Subscribe to the Blog
Be the first to read new posts