
Ray vs Dask vs Apache Spark™ — Comparing Data Science & Machine Learning Engines

Intro
Machine learning and data science are evolving at a breakneck pace. As rapidly as new technologies such as large language models and retrieval-augmented generation (RAG) are emerging, the tooling for data scientists and ML engineers is evolving equally quickly. These best-in-class tools, which we will cover in this blog, enable Spotify to develop personalized playlists, NASA to analyze satellite imagery, and OpenAI to train state-of-the-art large language models.
Over the past decade, machine learning (ML) and data science (DS) practitioners have rallied around Python as the language of choice. Powerful Python-based libraries such as Numpy, Pandas, and PyTorch process the intense computations required for ML and DS workloads, with native C/C++ implementations underneath. But data volumes continue to grow, and computations are becoming ever more complex, requiring workloads to scale beyond single-node Python applications that can run on one machine.
Compute engines such as Apache Spark™, Ray, and Dask enable ML and DS practitioners to scale out their Python workloads (and more) across many distributed machines. Each of these engines has unique strengths, with Spark offering unmatched resiliency for data pipelines, Ray enabling heterogeneous computing across GPUs and CPUs, and Dask supporting seamless upscales from single-node Python code to distributed applications.
In this blog, we will dive into the architecture of these engines and score them across key criteria to help you choose the best compute engine for your DS and ML workloads. This means that for an engine such as Apache Spark, which is versatile at general purpose ETL pipelines, we specifically focus on DS/ML workloads.
What is a distributed compute engine for ML and DS?
The purpose of a distributed compute engine for ML and DS is to scale programs (primarily in Python) across many machines. There are also single-node engines such as Polars, which accelerates programs by parallelizing them across multiple cores on a single machine.
This blog will focus on distributed compute engines, which are necessary for running terabyte and petabyte scale workloads that don’t fit on a single machine.
Use cases for ML and DS engines
Compute engines such as Spark, Ray, and Dask are designed to support various use cases across data science and machine learning. Let’s cover some of the most popular workload types.
Data science workloads often involve ad hoc exploration, where flexibility and compatibility with data science libraries are key. For example, data scientists may use these distributed engines to perform complex calculations on DNA sequencing data for genomics research or aggregate time series financial data for an investment firm.
Machine learning workloads typically start with a combination of unstructured data in a data lake and structured (or semi-structured) data ingested and cleaned through ETL pipelines. Various data and ML teams may further process and transform that data – for example, developing features to train an ML model. Next, the model is trained, using GPUs for advanced models like LLMs. Then teams must evaluate their models and potentially perform additional fine-tuning to improve the model quality. This is often a continuous process, with ML teams tuning or re-training on fresh data to keep models up-to-date. Lastly, the model is served for inference, making it available to an end user application.
The machine learning development process will vary between each organization, but the graphic below does a good job illustrating the diversity of workloads in the ML development lifecycle.

Beyond the quintessential use cases described above, ML and DS have a long tail of applications that are rapidly expanding. For example, some teams even incorporate ML model inference and vector embedding generation into their traditional ETL pipelines. ML and DS engines help practitioners scale all of these computationally intensive workloads beyond their laptop.
How ML and DS engines work
Compute engines use a master-worker architecture to distribute workloads across multiple machines (i.e., nodes) that perform parallel computations. Programs are divided into tasks, which are then scheduled by the master node and sent to the worker nodes. The “master-worker” terminology varies by engine, but the concept is similar.

The details under the hood of each engine expose its strengths and drawbacks.
- Are you ingesting and transforming data to feed your insights? You will be interested in Spark’s optimized planning and fault tolerance for fast, reliable data pipelines.
- Are you training ML models? You should learn about Ray’s shared-memory approach that enables effective scaling with GPUs and CPUs.
- Does your team live in Python and want seamless compatibility with familiar libraries? You should explore Dask’s Python-native architecture.
Most likely, your team would answer yes to multiple of the above questions. It’s important that you understand the underlying architecture of each engine in order to make sound technical decisions for your organization.
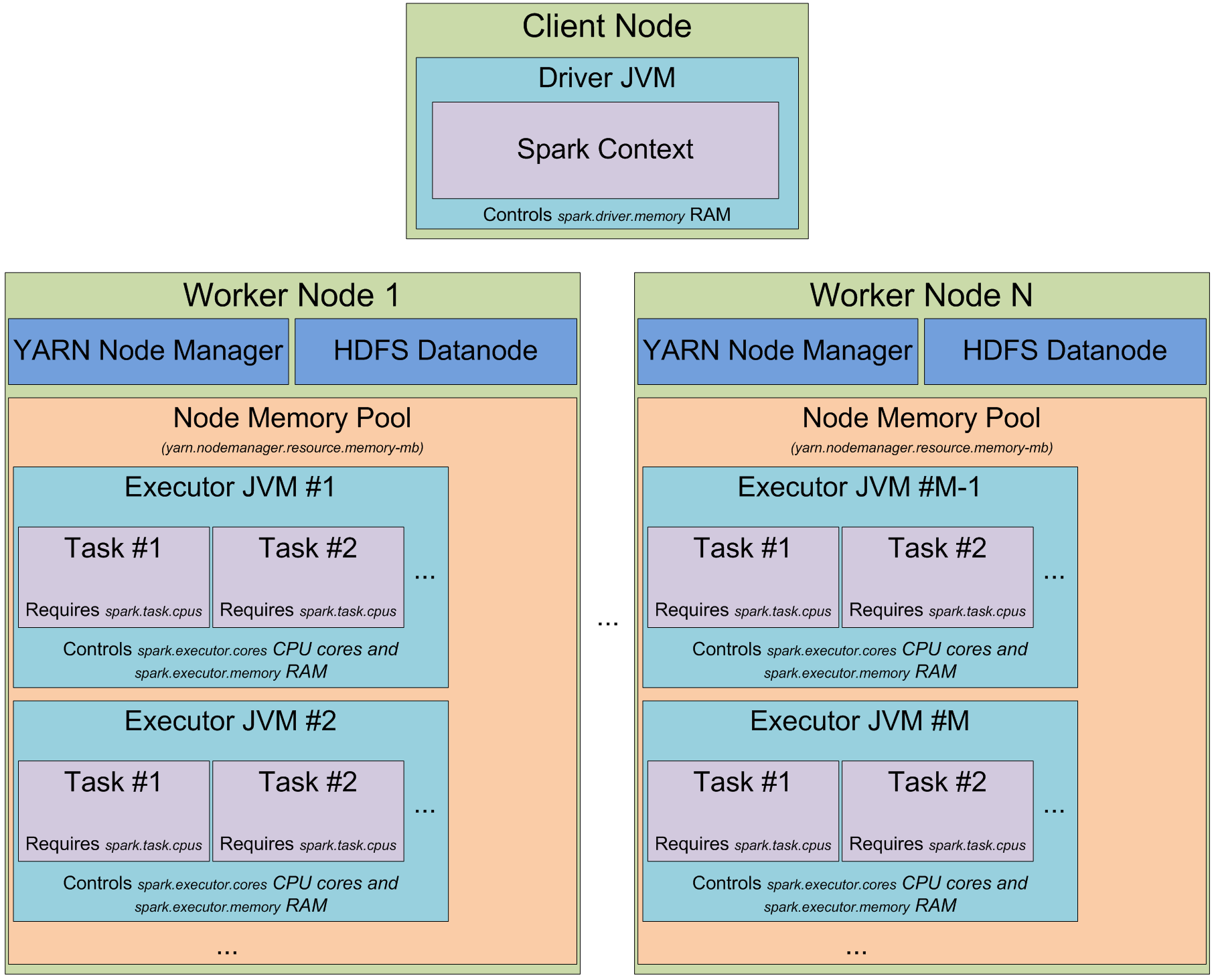
Apache Spark architecture
Apache Spark uses a driver node to plan and schedule tasks across worker nodes containing executors which run the tasks. The Spark Context in the driver node acts as the Spark application’s central coordinator, responsible for managing resources such as CPU and memory, creating Resilient Distributed Datasets (the fundamental data structures in Spark), and broadcasting variables (for sharing data efficiently across the cluster). Because Spark is written in Java, each node runs a JVM executor, which handles data persistence and transfers when executing Python code with PySpark.

When you submit a Spark job, it undergoes several stages. First, Spark creates a logical plan, where your query is parsed, validated, and optimized. This results in an optimized logical plan. Next, it generates a physical plan, detailing the exact execution strategy. This physical plan is then passed to the DAG Scheduler, which divides it into stages based on shuffle dependencies. Finally, each stage is further broken down into individual tasks, which are distributed and executed across the cluster.

Spark’s process of breaking queries into plans helps optimize performance by removing redundant calculations through lazy evaluation and minimizing data shuffles between nodes on the cluster. The DAG representation that Spark builds ensures fault tolerance in case any stage in the pipeline fails.
While Spark’s architecture offers many advantages in scalability, performance, and resiliency, it also limits compatibility with some ML and DS libraries in the Python ecosystem. For example:
- Pandas uses eager evaluation to execute operations immediately, while Spark leverages lazy evaluation. Pandas on Spark is a special library that bridges the gap, but doesn’t support the full pandas feature set.
- Popular ML libraries such as scikit-learn struggle with massive datasets that don't fit in memory and are intended to be executed on a single machine. Rather than bridging the gap to support such libraries, Spark developed its own library, MLlib, for scaling ML workloads.
Spark’s resilient, distributed architecture makes it a great general engine for working with structured and semi-structured data at scale. The design of Spark is generalized, so it works well for many data engineering workloads beyond ML and DS.
Ray architecture
Ray leverages a few simple primitives to distribute general Python applications across many machines:
- Task - Executes a stateless function remotely, potentially on a different machine. This enables users to control how they parallelize function calls.
- Object - Stores values from a task or a ray.put and shares them across nodes on the cluster. This enables data sharing between tasks running on different machines.
- Actor - An instance of a class that maintains a persistent state. This is useful for building applications that need to remember information between function calls, such as online machine learning models or simulations.
These primitives enable both stateless processing (for simplicity and fault tolerance) and stateful processing (for use cases like reinforcement learning). Ray also maintains an in-memory object store to optimize cross-machines data shuffles.
For the purpose of this blog, we will focus on Ray Data, the compute engine component of the broader Ray project. The Ray Data library builds on Ray Core, abstracting the primitives into Datasets. This enables developers to run distributed data processing workloads without worrying about the underlying details.
Ray also includes specialized libraries to assist in model training, tuning, and serving, as well as reinforcement learning.

Under the hood, a Ray cluster consists of a head node and one or more worker nodes. The head node contains a driver, which serves as the root of the program, and a Global Control Service server that manages critical metadata for the cluster such as the location of actors. Within each node is a Raylet, containing a scheduler and an in-memory object store which are accessible by all jobs on the cluster. The Raylets’ localized schedulers and object stores reduce network calls between nodes on the cluster and enable Ray to parallelize workloads effectively.

Ray’s architecture enables functions to be executed remotely across multiple machines. Each worker owns the execution and resolution of its assigned tasks, enabling the engine to parallelize tasks with high throughput and low latency.

Below is a basic example of how Ray enables a program to be parallelized across multiple machines.

While users primarily interact with Ray’s Python SDK, the Ray engine is written in C++. This enables fine-grained memory management and optimization for significant performance gains compared to higher-level languages.
Overall, Ray is a Python-friendly engine with powerful primitives and strong ML libraries out of the box. Ray’s architecture makes it great for handling heterogeneous compute workloads (using CPUs + GPUs). It’s not designed for ETL-heavy workloads (for example, it doesn't support joins), but excels at many data science and machine learning use cases.
Dask architecture
Dask was created with the primary goal of scaling Python programs. Dask uses collections to generate a task graph that can distribute work across multiple machines. Collections are the main abstraction in Dask, offering interfaces that are familiar to Python users:
- Array - Parallelizable NumPy arrays
- DataFrame - Parallelizable Pandas DataFrames
- Bag - Parallelizable Python lists (for operations like map, filter, and groupby)
- Dask-ML - Scalable versions of ML libraries, including Scikit-Learn and XGBoost
- Delayed - Lower-level interface for parallelizing custom algorithms that don’t fit into other interfaces
- Futures - Lower-level interface for executing computations immediately and asynchronously (as opposed to lazy execution)
The task graph enables Dask to optimize execution by processing data in parallel, eliminating redundant computations with lazy execution, intelligently distributing work, enabling fault tolerance, and more.

After Dask generates a task graph for your program, the scheduler distributes the tasks locally or across distributed worker nodes that perform the computations. In addition to its Pythonic interfaces, Dask constructs and optimizes the graph in pure Python, making it easy for Python developers to profile and comprehend.

Dask’s architecture allows it to work seamlessly with Python programs, natively supporting libraries such as NumPy, Pandas, Scikit-learn, XGBoost, and CuPy (for GPU acceleration). This approach makes it easy for ML and DS practitioners to scale out existing Python workloads without significant code rewrites, while still offering flexibility for more advanced algorithms with low-level interfaces like Dask Delayed and Futures.
Using these technologies together
While these compute engines are distinct, it’s also possible to run Spark on Ray, Ray on Spark, and Dask on Ray. These combinations are less commonly used, but are worth understanding for the role they play in the ecosystem.
As we’ll cover in this blog, each engine has its own strengths and weaknesses, which makes it potentially useful to combine engines for handling multiple use cases. For example:
- Spark on Ray allows you to read and transform data in Spark and train models in Ray without managing infrastructure for multiple engines.
- Ray on Spark can deploy Ray clusters on Spark worker nodes, enabling data sharing and common infrastructure between the two engines.
- Dask on Ray provides a special Dask scheduler that enables developers to run familiar Python workloads via Dask, while leveraging the scalability advantages of a Ray cluster.
How to choose a compute engine for ML and DS?
Now that you understand the internals of how each engine operates, you may be wondering which one you should pick for your ML or DS workload. Your requirements for a compute engine will heavily depend on your use cases. There are countless factors, and you may start by asking yourself questions like the following:
- What is the scale of my data and workloads?
- Will I have complex ML workloads that require GPUs?
- Do I need to ingest and model structured data to power my DS and ML workloads?
- How important is Python compatibility, and how familiar is my team with distributed systems?
- What types of data am I working with – text, images, tables, tensors, etc.?
Your compute engine decisions may significantly vary depending on the answers to these questions, and the answers may even change over time!
In the next section, the feature comparison, I will score each engine on a comprehensive list of capabilities, and will provide the questions you should ask to understand the current and future needs of your organization.
The key is understanding the fundamentals to make an informed decision on the engines to test and deploy for your use cases. You may find that it’s best to mix and match engines, for example, pairing Apache Spark (for data preparation and feature engineering) with Ray (for training models).
The goal of this comparison is not to declare a winner or say one engine is better than the other. The goal is to give you a foundation of research so that you can analyze your own use case and make the best decision for your team.
Feature Comparison
In this next section, we will dive deep into a head-to-head comparison of the engines, evaluating them across various aspects of engine design, developer experience, ecosystem, storage integrations, data science workloads, machine learning workloads, and non-Python workloads.
In each section I assign a grade of A = best solution, B = good solution, C = below average for how well the engine compares, based on the attribute being measured. After the 1-by-1 analysis, I also created a metascore where I awarded 3pts for every A, 2 for a B, 1 for a C. The metascore is a normalized sum of all points across all features and categories. Below are the rankings from the metascore:

The purpose of this blog is not to declare a single winner or loser amongst the engines, but to provide a base of research that you can use to inform your own decision making. It is important to note that this compiled metascore is not a perfect scientifically measured score. For example, perhaps not all features should be given equal weights.
Is it possible to create an objectively perfect score? I don’t think so, so take my analysis as a starting point to do your own research. A few of the ratings below could be interpreted as subjective – if you disagree with a rating, reach out to me and I would love to learn from your perspective and perhaps adapt my conclusions.
Now let's dive into the comparisons!
Cost-Performance
Cost-performance is a measure of how much performance you get for the money spent. It’s often measured by comparing the time spent for the same machine type to process the same workload across different engines.
The cost-performance of each engine varies significantly across use cases. Below are some publicly-available benchmarks:
- With Ray, Amazon achieved 91% cost efficiency gains over Spark for an exabyte-scale ingestion workload through Ray’s optimizations such as its shared in-memory object store and C++ implementation for better memory management
- A benchmark comparing Dask Distributed vs. Dask on Ray found Dask on Ray to have 3x better cost:performance than Dask Distributed for a 3 PB workload
- Bodo’s benchmark found Ray to have 5-10x worse cost:performance than Spark and Dask.
- Another benchmark from a Dask contributor initially found Dask Dataframes to be 5x faster than Spark Dataframes; the author later realized the results were flawed due to inherent bias in the experiment setup
Given the variance in cost efficiency across these engines, we will hold off on assigning grades for this section. However, the following guidelines may be a helpful starting point for thinking about the cost:performance implications of each engine based on your use cases:
- Spark is excellent at applying a consistent set of operations to large datasets through its ability to parallelize data. This makes it the typical go-to engine for ETL and data preprocessing.
- Ray is optimal for memory-intensive workloads that combine data preprocessing and ML model training, especially those combining CPU and GPU instances. Ray’s architecture enables fully pipelined execution, which is optimal for ML workloads such as reinforcement learning, time series forecasting, and hyperparameter search.
- Dask is the most lightweight of these engines, and seems to perform best on medium-scale workloads (1-10 TB).
Design
These compute capabilities are key to efficiently run and scale workloads. Many models now require the use of GPUs, and in some cases can greatly benefit from heterogeneous compute with CPUs and GPUs. Scheduling is also important, with certain engines offering the ability to prioritize workloads and others offering all-or-nothing gang scheduling, a critical capability for deep learning workloads.
🏆 Best in class: Ray Data
❌ Worst in class: Dask
|
Feature / Engine |

Ray Data |

Dask |

Apache Spark |
|
Scheduling Efficiency |
A
Designed to scale ML workloads, with built-in support for gang scheduling natively via KubeRay and load-based autoscaling.
|
B
Load-based autoscaling with jobqueue and adaptive deployments. Gang scheduling is not supported (Dask on Ray tries to provide this but does not seem to be actively maintained). |
B
Requires external libraries such as Apache Yunikorn or Spark on Ray for gang scheduling. |
|
Scaling Up and Down
How does the engine scale when workload demands ebb and flow? |
B
Ray offers autoscaling with built-in controls for up/down scaling speed, along with programmatic scaling controls. Ray optimizes for task parallelism, so it’s good at scaling when computation needs change, but less so when data volumes are changing. |
B
Dask does not offer native resource scaling, but scaling is supported via Kubernetes, YARN, and other resource managers. Adaptive Deployments through resource managers enable autoscaling for Dask clusters based on information collected by the Dask scheduler. |
B
Natively supports advanced autoscaling via dynamic allocation, but requires significant tuning to avoid resource wastage. |
|
GPU Support
How well does the engine support GPUs and heterogeneous compute resources (CPUs + GPUs)? |
A
Allows granular mapping of heterogeneous computing (CPUs + GPUs) resources to tasks, with per-task accelerator-based scheduling and awareness of different GPU types. |
C
No native GPU awareness, but supports GPUs via external libraries like RAPIDS cuDF and CuPy. |
B
Spark offers GPU-aware scheduling, with additional GPU capabilities supported through the RAPIDS library. However, it does not offer finer-grained control for heterogeneous computing (CPUs + GPUs). |
|
Job Concurrency
How does the engine handle simultaneous applications/jobs? Can users configure scheduling and priorities? |
C
Ray generally does not support running multiple applications/jobs on the same Cluster. |
B
Dask technically supports shared clusters, which can be facilitated through the Dask gateway. Still, users are recommended against running multiple applications/jobs on a shared cluster since Dask can only execute work first-come-first-serve. |
A
Spark’s thread-safe scheduler can safely parallelize multiple jobs within a single Spark application. Spark offers built-in capabilities for FIFO and fair scheduling, as well as easy ways to share cached data across jobs. Dynamic resource allocation also helps applications relinquish resources on the cluster when they are no longer needed. |
|
Task Concurrency
Can the engine parallelize and concurrently execute tasks within an application/job? |
A
Databricks suggests that Ray offers a higher degree of parallelism than Spark. Ray is better designed around tasks and state at its core, through Ray’s actor-based concurrency model. Ray offers various workload scheduling strategies at the task/actor levels. Ray has no native support for priorities, which can be managed via the KubeRay integration with Kueue. |
A
Dask offers a distributed scheduler that parallelizes tasks from the task graph. Many Dask functions support a priority arg used by the scheduler to prioritize tasks. Dask can also prioritize tasks automatically to optimize performance. |
B
Spark’s task parallelism is driven by data parallelism. It divides the data into partitions and executes tasks on them in parallel. However, Spark’s DAG scheduler schedules tasks stage by stage, where tasks in a subsequent stage do not begin until the previous stage completes. This can limit use cases like ML training that need all tasks working together concurrently.
|
|
Memory Management
How resilient is the engine to out-of-memory (OOM) errors? |
A
Ray’s memory monitor detects high memory usage and automatically kills tasks or actors to free up memory and supports disk spilling to help avoid OOM errors. This can cause applications to run slower on Ray, but makes the cluster more resilient to OOM errors. Ray is written in C++, enabling optimal memory management. Ray’s shared-memory architecture also enables optimal memory efficiency. |
B
Dask supports spilling data to disk and can automatically pause or kill workers based on memory usage. Dask’s Active Memory Manager can also help optimize memory usage at the cluster level. Dask is written in Python, leading to some memory overhead (as compared to C++). Benchmarks have found that Dask standalone is less memory-efficient compared to running on Ray. |
B
Spark parallelizes workloads across machines and can spill data to disk, but does not offer the same OOM prevention capabilities as Ray. For memory-intensive workloads, Spark often requires tuning to avoid OOM errors. Spark is written in Java, so the JVM for each executor adds memory overhead. |
|
Fault Tolerance
How resilient is the engine to failures, and how seamlessly does it ensure data processing continuity? |
B
Ray provides fault tolerance through built-in checkpointing, task retries, and actor restarts. Ray uses lineage reconstruction to recompute data when an in-memory object store is lost. However, given that Ray jobs can be stateful, certain cases are non-recoverable, such as object owner failures or objects created by ray.put, requiring additional manual effort for recovery. |
A
Dask provides fault tolerance by recomputing the task graph upon failures. Dask is resilient to worker failures, though, similar to Spark, data may be lost if the scheduler fails. |
A
Spark inherently provides fault tolerance through its RDD lineage and task rescheduling to recompute lost data, using the state maintained on the driver node. Further, Spark tasks and stages are retried upon failure automatically. |
Developer Experience
The best technologies meet users at their zone of genius. Data scientists and ML practitioners often focus less on distributed systems and infrastructure and more on algorithms, statistical modeling, and domain-specific expertise (such as in finance or medical research).
Python is typically the language of choice for these practitioners due to its simplicity and rich ecosystem of DS/ML libraries. An engine must be capable of adapting to a practitioner’s existing Python workflows without a significant learning curve or migration efforts.
🏆 Best in class: Dask
❌ Worst in class: Apache Spark
|
Feature / Engine |
Ray Data |
Dask |
Apache Spark |
|
Python API & SDK Clarity
How intuitive are the Python APIs and what is the learning curve for a Python developer? |
A
Ray is Python-native, which allows the use of existing python libraries transparently, while Ray provides lighter weight task orchestration. Ray also provides an intuitive Python API with a low learning curve for Python developers. |
A
Dask closely mirrors popular Python libraries such as NumPy and Pandas, enabling good compatibility with the Python ecosystem and a low learning curve for Python developers. |
B
PySpark offers a Python interface over the underlying JVM execution via py4j. Users can use Python native libraries, but computations incur the additional overhead of serialization/deserialization between the JVM executor and the Python process executing native functions. |
|
Orchestration & IDE Integrations
How well does the engine integrate with common Python development environments (e.g., Jupyter notebooks, Airflow, etc.)? |
A
Ray integrates with Jupyter and popular orchestration frameworks, including Airflow, Prefect, LaunchFlow, and more. |
A
Dask offers a deep integration with Jupyter, along with Airflow and Prefect integrations for orchestration. |
A
Spark offers rich integrations with the developer ecosystem, including Airflow, dbt, Tableau, Jupyter, and more. |
|
Ease of Migration from Single-Node Python
How easily can a developer move their single-node Python code to the engine for parallelized computing? |
B
Ray can parallelize existing Python workloads with minor code changes. Python developers can use functions like from_pandas and from_numpy to convert existing objects into Ray’s Dataset objects. Ray also supports libraries for compatibility with the Python ecosystem such as Modin (Pandas) and Joblib (scikit-learn). |
A
Dask is designed to natively scale out Python, offering parallelized versions of NumPy arrays and Pandas DataFrames. Existing Python code often works with Dask with just a change in import statements, offering the easier migration path from single-node Python. Dask offers methods like from_pandas for easy conversion from pure Python. |
C
Moving from single-node Python to Spark typically requires substantial code changes. Spark offers functions like from_pandas and to_spark to help with manual workload migration. |
|
Ease of operations for Python developers
How easily can a Python developer maintain and troubleshoot these programs?
|
B
More pythonic. Program debugging is fully in Python. However, debugging the Ray cluster can be more complex since Ray is written in C++. Some of this is unavoidable in achieving high performance. |
A
Dask is written in Python, so debugging applications are familiar to Python developers. |
C
Spark is written in Java, which is commonly cited as a learning curve for Python developers debugging applications. When programs fail, developers need to debug java + python stack traces |
|
Documentation & Examples
How comprehensive and clear is the documentation and how practical are the examples? |
A
Ray provides clear documentation with a large gallery of examples and a comprehensive whitepaper explaining the engine internals. |
A
Dask offers clear and comprehensive documentation with easy quickstarts and plenty of realistic examples. |
A
Spark is a highly mature project with solid documentation and countless examples online. A Google search for “Apache Spark tutorial” returns ~18M results. |
Ecosystem Support
Most DS and ML workloads involve working with libraries such as Pandas dataframes, NumPy for classical ML, and PyTorch for deep learning. Compute engines should be compatible with Python’s rich ecosystem of DS and ML tooling, as well as deployment and orchestration frameworks for productionizing workloads. It’s also a bonus if an engine offers native capabilities for ML and DS use cases.
Compatibility is a challenge when moving from single-node to distributed systems, and each engine solves this slightly differently. Since much of the DS and ML ecosystem integrates with Pandas, it’s key for these distributed engines to achieve maximal compatibility with the Pandas API.
🏆 Best in class: Ray Data
❌ Worst in class: Apache Spark
|
Feature / Engine |
Ray Data |
Dask |
Apache Spark |
|
Deployment Frameworks
What deployment frameworks are supported natively? |
A
Ray integrates deeply with Kubernetes, with its native KubeRay operator and Kueue for priority-based gang scheduling. It also integrates with Apache Yunikorn, YARN, and several more frameworks. |
A
Dask integrates many deployment frameworks, including Kubernetes (with a native operator), YARN, and more. Natively supports priority-based scheduling. |
A
Spark integrates with Kubernetes (including a mature operator ), YARN, and Apache Yunikorn, along with many other deployment frameworks. |
|
Python DataFrames
Does the engine offer native DataFrames and support pandas? |
A
Ray’s native Dataset API can hold multiple DataFrames, in addition to other formats. Ray offers methods like from_pandas to convert Pandas DataFrames to a Ray Dataset for easy migration. Ray also supports distributed pandas DataFrames with Modin to run existing code without migration. |
A
Dask DataFrame aims to exactly match the pandas API. However, coverage is limited. Modin is an option for pandas on Dask with pandas API coverage closer to 100%. |
B
Spark has a native DataFrame API. This is pandas-compatible via the Pandas API on Spark ( fka Koalas ), although coverage of the pandas API is limited and migration from standard pandas can take a while. |
|
Classic ML Ecosystem Support
Does the engine support libraries like NumPy, scikit-learn, and XGBoost ? |
A
Ray’s from_numpy method translates Numpy ndarrays to a native Ray Dataset. Ray also supports scikit-learn and is compatible with XGBoost via Modin DataFrames. |
A
Dask-ML provides native compatibility with Numpy, scikit-learn, and XGBoost. |
A
Spark’s MLlib is fully compatible with NumPy objects, joblib-spark supports scikit-learn, and XGBoost offers PySpark compatibility. |
|
Deep Learning Ecosystem Support
Does the engine support libraries like PyTorch, TensorFlow, Lightning, and jax ? |
A
Ray Train supports many deep learning libraries, including Tensforflow, PyTorch, and Lightning. Ray can also be used to scale out jax. |
A
Dask has official integrations with PyTorch and TensorFlow. According to Github issues, Dask also supports jax and Lightning. |
A
Spark’s TorchDistributor provides PyTorch and Lightning compatibility. Horovod enables distributing TensorFlow on Spark. |
|
Native ML/DS Libraries
Does the engine offer built-in libraries or functions beneficial for ML/DS? |
A
Ray comes with AI libraries for data preprocessing, model training/tuning/serving, and reinforcement learning. These native libraries complement Ray Data and are unmatched by the other engines. |
C
Dask-ML offers distributed versions of some popular ML algorithms, but Dask generally relies on external Python ML libraries. |
B
Spark offers MLLib and spark.ml, NumPy-compatible libraries, useful key ML algorithms and ML workflow utilities. |
Storage Integrations
Engines should be able to process both structured and unstructured data, as real-world applications often require data from diverse sources. Data lakehouse projects, such as Apache Hudi / Apache Iceberg / Delta Lake, are essential pieces of the DS and ML ecosystem, powering capabilities like feature stores and retrieval augmented generation (RAG). Unstructured data support is also critical as techniques like natural language processing and computer vision, as well as libraries like TensorFlow, have exploded in popularity.
🏆 Best in class: Apache Spark & Ray Data
❌ Worst in class: Dask
|
Feature / Engine |
Ray Data |
Dask |
Apache Spark |
|
File Format Support
Read/Write support for Parquet, JSON, ORC, Avro, Lance, etc.? |
A
Read & write support for Parquet, JSON, ORC, Avro, CSV, Lance, and other file formats. |
B
Read & write support for CSV, Parquet, and Avro. Read-only support for ORC and JSON.
|
A
Read & write support for Parquet, JSON, ORC, Avro, CSV, Lance, and other file formats. |
|
Lakehouse/Table Format Support
Read/Write support for Hudi, Delta Lake, Iceberg? |
B
Read-only support for Hudi, Delta Lake, and Iceberg |
B
Read-only support for Delta Lake and Iceberg. No official Hudi integration, but it may be supported via hudi-rs. |
A
Read & write support for Hudi, Delta Lake, and Iceberg |
|
Unstructured Data Support
Support for processing text, images, video, audio, binary, vectors, tensors, etc.? |
A
Read & write support for images and TensorFlow records. Read-only support for text, video, audio, TensorFlow datasets, binary, and torch datasets. |
A
Dask supports images, text, video, and audio via its Bag and Delayed interfaces. Dask Arrays can efficiently represent and process large multi-dimensional arrays, including vectors and tensors. |
C
Read & write support for text. Read-only support for binary, images, and LIBSVM. No support for reading TensorFlow and torch DataSets, (but can convert Spark dataframes to these formats with petastorm ). |
|
Vector Search Support
Does the engine support efficient search on vectors? |
A
Ray natively supports reading & writing from vector databases through Python libraries such as PyMilvus ( example ), Weaviate’s Python client, and Pinecone’s Python SDK ( example ). |
A
Numpy (and thus, Dask Arrays ) supports vectorized processing to efficiently handle vector search. Dask supports the full Python ecosystem, allowing it to work with PyMilvus, Weaviate’s Python client, and Pinecone’s Python SDK. |
A
Supports reading and writing dense and sparse vectors. Spark integrates with vector databases like Weaviate, Milvus, and Pinecone. Vector search indexes can be built using Spark + lakehouse format/hudi. |
Data Science Workloads
Data science use cases vary widely, with the key engine capabilities being flexibility to process large, unmodeled datasets, and compatibility with specialized data science libraries. These compute engines power diverse capabilities, such as scientific computing at CERN, time series analysis at JP Morgan Chase, and geospatial data analysis at Safegraph.
🏆 Best in class: Apache Spark and Dask
❌ Worst in class: Ray
|
Feature / Engine |
Ray Data |
Dask |
Apache Spark |
|
Exploratory Data Analysis
How easily can the engine process joins, filters, and aggregations on large, un-modeled datasets? |
B
The Ray Client and Jupyter integration enable interactive workloads on Ray, and Modin enables support for pandas. However, these use cases typically use just CPUs and don’t require the complexity of Ray’s task-centric parallel primitives. |
A
Dask’s lightweight architecture, Jupyter notebook integration, and Python compatibility make it a great fit for exploratory data analysis at distributed scale.
|
A
PySpark offers interactive execution and integrates with Jupyter, though it requires code changes from pure Python programs, it balances that with R support for statistical analysis. Spark SQL makes it easy to explore data. |
|
Speed of analysis
How quickly can data scientists run different analyses repetitively on the same data set? |
B
It’s possible to cache data in Ray’s object store, but the lack of SQL/dataframe level abstractions makes Ray ill-suited for repetitive exploration. |
A
Dask also supports persisting dataframes like Spark across the cluster. |
A
Features like built-in caching enable few ms-second level responses for exploratory data analysis on top of Spark’s in-memory columnar format.
|
|
Large-Scale Data Cleaning and Transformation
How well does the engine support complex data cleaning on large, semi-structured datasets? |
C
Ray typically focuses on last-mile processing. The Ray Data API offers useful built-in transformations for feature engineering, but Ray is not specifically optimized for data pipelines and does not support joining multiple datasets. |
B
Dask supports most operations necessary for cleaning and transforming data through its support for Python libraries, but it does not offer the same level of optimized execution that Spark does for logical plans and data shuffles. |
A
Spark SQL and DataFrame APIs are highly optimized for parallelizing ETL pipelines with structured and semi-structured data. |
|
Scientific Computing
What capabilities does the engine have to process data generated by scientific instruments (telescopes, sequencers, etc.) and perform numerical computing tasks (linear algebra, matrix operations)? |
A
Databricks suggests that Ray is optimal for scientific computing due to its ability to scale out single-node Python programs without significant code refactors. |
A
Dask is designed to support scientists and researchers across diverse domains. Dask offers first-class support for Python libraries like Numpy and Scikit-learn so scientists can easily bring existing Python workloads. |
B
Fermilab found that Spark performance was suboptimal for scientific data formats like ROOT trees (common data format in physics). Despite the data format limitations, Fermilab and CERN both advocate that Spark’s parallelization and scaling is valuable for scientific computing use cases. |
|
Time Series Forecasting
How easily does the engine support the processing of high-frequency time series data (financial data, sensor logs)? |
A
Databricks recommends using Ray for time series forecasting. Ray docs include time series examples and companies like Nixtla, Kevala, and JP Morgan Chase use Ray to scale their time series forecasting. |
A
Popular time series library, sktime, suggests using Dask for distributed time series forecasting. Dask also includes time series examples in the docs and supports a time series object. Dask is used by Splunk and the National Science Foundation to scale time series forecasting. |
B
Organizations like Sleep Number and Workday use Spark to efficiently process time series data. Specialized time series libraries for Spark exist ( flint, thunder ), but are not actively maintained. |
|
Geospatial Data Analysis
How well does the engine support large geospatial datasets (satellite imagery, GPS data)? |
A
Ray is able to run Geopandas in a distributed way for faster and more scalable geospatial analytics compared to single-node solutions. Ray also supports the GeoTiff data format through its read_binary_files API. |
A
Dask offers first class support for Geopandas through the dask-geopandas library. AWS offers a solution guide for analyzing terabyte-scale geospatial datasets with Dask. |
B
Spark is capable of processing geospatial data through its integration with Apache Sedona (formerly Geospark). Companies like Safegraph and Wejo use Spark for geospatial data use analysis. |
Machine Learning Workloads
The ML development lifecycle typically uses data pipelines to clean and model datasets and features. This data is then used to train, tune, and serve the model. Developers require different capabilities from their engine at each stage of the lifecycle, which often leads to some mixing and matching to build an optimal end-to-end pipeline.
Furthermore, certain engines are better fit for specialized use cases, such as generative AI (which requires GPUs and immense scalability) and real-time ML (which requires low-latency data streaming capabilities).
🏆 Best in class: Apache Spark & Ray Data
❌ Worst in class: Dask
|
Feature / Engine |
Ray Data |
Dask |
Apache Spark |
|
Feature Engineering
How well does the engine support building and executing complex data pipelines for feature engineering in ML/DS? |
C
Ray typically focuses on last-mile processing. The Ray Data API offers useful built-in transformations for feature engineering, but Ray is not specifically optimized for data pipelines and does not support joining multiple datasets. |
B
Dask supports most operations necessary for cleaning and transforming data through its support for Python libraries and dask_ml ’s built-in preprocessing APIs, but it does not offer the same level of optimized execution that Spark does for logical plans and data shuffles. |
A
Spark SQL and DataFrame APIs are highly optimized for parallelizing ETL pipelines with structured and semi-structured data. With Spark Streaming, Spark can also be used to build real-time features. |
|
ML Model Training, Tuning, and Serving
How suitable is the engine for ML model training, tuning, and serving/inference? |
A
Ray supports model parallelism for distributed training and inference through its actor model. It also offers native support for GPUs and first-class support for heterogeneous computing to leverage the strengths of both CPUs and GPUs. Ray includes built-in libraries for training, tuning, and serving. |
B
Dask offers the dask_ml library with some APIs for classical ML model training, in addition to supporting Python libraries like PyTorch and Tensorflow that enable training, tuning and inference. While Dask can handle these workloads, Ray is a better choice at scale as it is more efficient in managing GPU, CPU, and memory resources. |
B
Spark’s MLlib supports training, tuning, and inference for most classical ML models and TorchDistributor enables deep learning. Inference is supported by pyspark.ml. RAPIDS enables Spark to run on GPUs. However, Spark can be inefficient for these workloads, as data transfers (ie. shuffles) become expensive on GPUs when data exceeds the available memory. |
|
Generative AI
How suitable is the engine for running generative AI workloads? |
A
Ray is best at scaling GPU-intensive workloads like generative AI. The Ray Train library provides useful APIs for model training, while Ray Core offers advanced configurability (necessary for 100+ node workloads ). OpenAI and Cohere use Ray to coordinate large language model (LLM) training on GPUs. |
C
Similar to Spark, Dask can connect to generative AI tools like LangChain through their Python library, but Dask is not typically used as a compute engine at the scale required for generative AI workloads. |
B
Spark itself is not ideal for scaling generative AI inference on GPUs, and focuses more on CPU-based workloads. Spark still plays a role in generative AI, as key tools like MLflow and LangChain can read from Spark through integrations.
|
|
Real-time ML
How well does the engine support streaming-style, low-latency ML workloads? |
A
While Ray does not focus on data ingestion, the Ray Data library supports streaming execution to enable last-mile streaming transformations for real-time ML. |
C
Dask no longer offers native support for streaming data. Users must set up streaming semantics manually or bring on an external library like Streamz. |
A
Spark offers first-class support for real-time data through Structured Streaming. Insider uses Spark to power their realtime feature extraction. |
Non-Python Workloads
While Python is the primary language for DS and ML practitioners, SQL is widely used for data exploration and building dashboards/visualizations. R is also useful and popular in the data science community. Java and Scala are widely used by data engineering teams for data pipelines, which are important for ingesting and modeling the data. Specifically, Spark/Flink’s built-in ML libraries power tons of large-scale production data science and ML pipelines as well.
🏆 Best in class: Apache Spark
❌ Worst in class: Ray Data
|
Feature / Engine |
Ray Data |
Dask |
Apache Spark |
|
SQL Support
Does the engine support SQL? |
C
Ray can read from SQL databases, but does not have its own SQL execution engine. |
B
Dask has no parser or query planner for SQL, but can support some Presto SQL syntax via the dask-sql library, which is built atop Python. No JDBC support for connectivity to the SQL ecosystem. |
A
Spark SQL is ANSI SQL compliant and provides built-in optimizations. JDBC is supported via Hive Thrift Server for connectivity to SQL Editors and visualization tools. |
|
R Support
Does the engine support R? |
C
No support for R. |
C
No support for R. |
A
Spark supports R via SparkR. |
|
Java & Scala Support
Does the engine support Java and Scala? |
A
Ray has surprisingly good Java support and the ability to run JVM applications on Ray clusters, just like Python. |
C
No support for Java and Scala. |
A
Spark natively supports Java and Scala. |
Commercial and OSS support
At the end of the day, a technology is most useful when a supportive and engaged community backs it. With new workloads and libraries constantly emerging, it’s important to have an active community around these open source projects to drive continuous innovation and provide support for any challenges. Here, we look at the volume and diversity of usage/contributions, as well as commercial support for each project.
🏆 Best in class: Apache Spark & Ray
❌ Worst in class: Dask
|
Feature / Engine |
Ray Data |
Dask |
Apache Spark |
|
Github Momentum
Github stars, an indication of how popular a project is |
A
36.1k stars (as of Mar 2025) |
B
13k stars (as of Mar 2025) |
A
40.8k stars (as of Mar 2025) |
|
OSS Contributors
# of contributors w/ commits in the last month |
A
29 contributors (in Feb 2025) |
C
4 contributors (in Feb 2025) |
B
15 contributors (in Feb 2025) |
|
Contributing Companies
What companies have the most PR contributors to the project? |
A
Anyscale, Google, UC Berkeley, Microsoft, Ant Financial, ByteDance, Amazon, VMWare, Intel |
A
Nvidia, Coiled, Microsoft, Quantsight, Google, Anaconda, Voltron Data, Shopify, Met Office |
A
Databricks, Microsoft, Google, IBM, Tencent, Alibaba, Cloudera, LinkedIn, Facebook, Intel |
|
Commercial offerings
What are the commercial product offerings? |
B
Anyscale ($260M raised) |
C
Coiled ($26M raised) |
A
Databricks ($13B+ raised) Amazon EMR & Glue Google DataProc Microsoft Fabric And many more… |



Case studies
Beyond the feature capabilities, it can be incredibly insightful to read the stories of companies using these technologies for real-world, production use cases.
You’ll find plenty of case studies for these projects online. Below are some of my favorites, which helped in the research for this blog.
Apache Spark
- NVIDIA: Spark RAPIDS ML for GPU Accelerated Distributed ML in Spark Clusters
- Riot Games: A Case Study on Data Processing and Analytics with Spark and MLlib
- Safegraph: Building Foot-Traffic Insights Dataset
- FermiLab: Exploring the Performance of Spark for a Scientific Use Case
- Insider: Real-Time Feature Extraction with Spark Structured Streaming
Ray
- OpenAI: How Ray, a Distributed AI Framework, Helps Power ChatGPT
- Uber: How Uber Uses Ray to Optimize the Rides Business
- Netflix: Heterogeneous Training Cluster with Ray
- Pinterest: Last Mile Data Processing with Ray
- Cohere: Scalable training of language models using Ray, JAX, and TPUv4
- Amazon’s Exabyte-Scale Migration from Apache Spark to Ray on Amazon EC2
Dask
- Sidewalk Labs (Google Earth): Civic Modeling
- Capital One: Adding Dask to Your Existing Pipeline
- Microsoft AI: Scalable Geospatial Data Analysis with Dask
- Oxford University: Genome Sequencing for Mosquitos
- University of Wisconsin: Satellite Imagery Processing
Unleash your data
Choosing the right compute engine (or engines) is a strategic decision that can supercharge your data science and machine learning teams for years to come. Each engine brings its own unique strengths:
- Apache Spark for core data ingestion and transformation pipelines
- Ray for last-mile processing and scaling ML workloads
- Dask for lightweight speed and Python ecosystem compatibility
No matter which engine(s) you choose, the real power comes from the freedom to mix and match engines, scale with confidence, and unlock a wide ecosystem of capabilities without being locked into one architecture.
That’s where Onehouse comes in. At Onehouse, we believe in open data, open engines, and open possibilities. Our platform brings:
- Seamless integration with DS and ML compute engines
- Fast and incremental data ingested directly to your lakehouse storage
- Automatic table management for Hudi, Iceberg, and Delta tables
- One source of truth, regardless of how many engines touch your data

With Onehouse not only do you get fully managed ingestion, incremental ETL, and table optimizations, but now with our newly released Open Engines platform you now have the ability to launch clusters with a variety of open source engines at the click of a button:

Ready to tackle your analytics challenges? We would love to chat! Contact Onehouse at gtm@onehouse.ai to get the details behind how we did these comparisons and how you can achieve 2-30x performance gains seamlessly running Spark, Ray, or Dask.

Read More:





{kind=link}

Subscribe to the Blog
Be the first to read new posts