Lakegres: Real-Time Lakehouse Queries from Any Postgres Client
The world’s first lakehouse serving layer with database capabilities like indexing and caching. Built for both machines and humans. Handling high-QPS, low-latency queries from AI agents as well as heavy analytics.
Finally, a Serving Layer for the Lakehouse
™ or Apache Iceberg™ tables through a highly available, autoscaling, Postgres-compatible SQL endpoint. With intelligent indexing and caching, Lakegres delivers database-like responsiveness for interactive analytics and agent-driven exploration without ever moving data out of your lakehouse.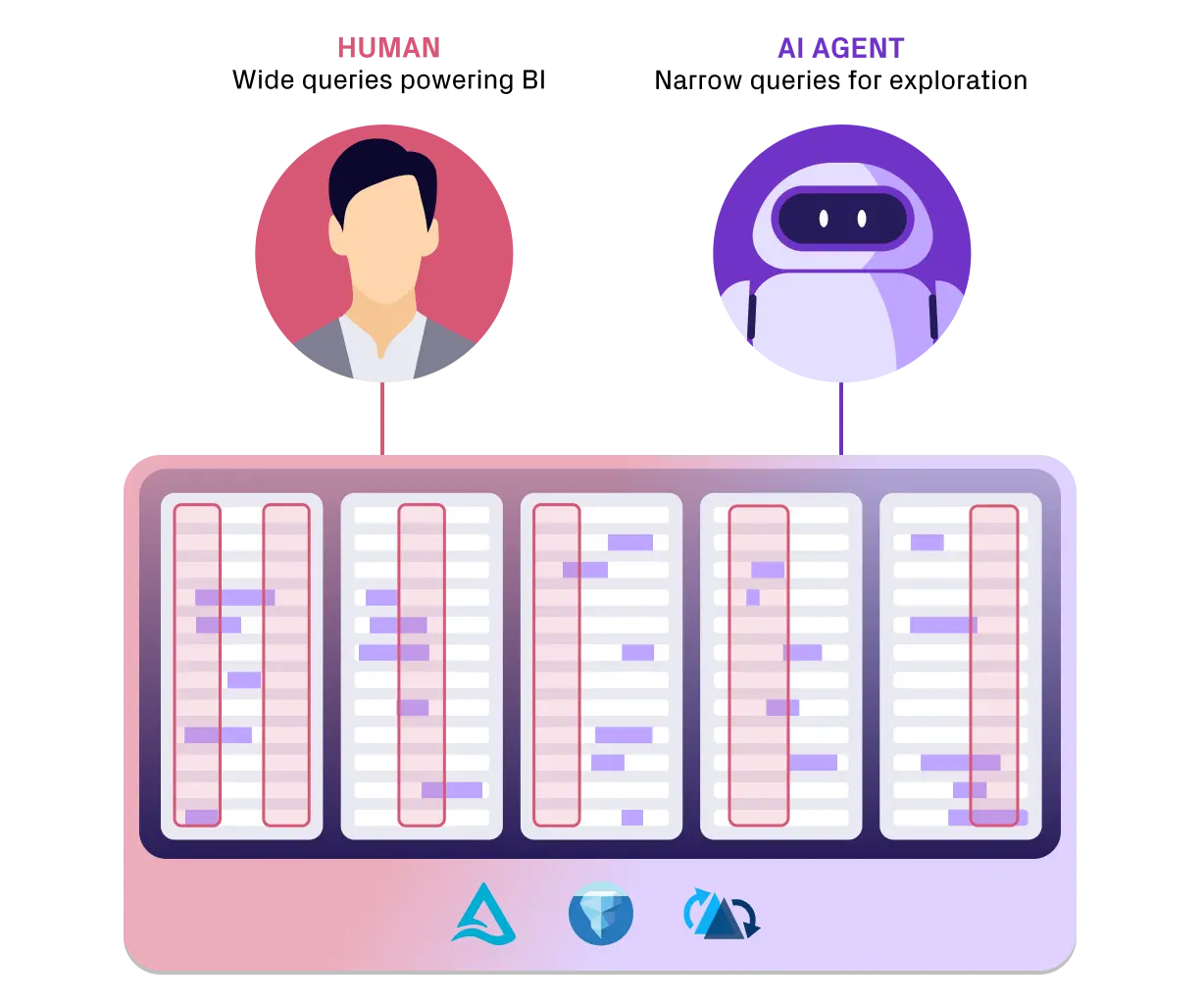
Full-Fledged Database Functionality
Automatic indexing and multi-tier caching deliver low-latency SQL directly on Iceberg/Hudi without copying data into a warehouse. Your AI Agents can do large joins in O(N) time with high-cardinality filters in seconds and needle-in-haystack lookups in milliseconds.
High QPS, Low-Latency Agent-Scale Querying
Trino and Apache Spark™ scale poorly beyond low-qps, low-concurrency querying due to architectural limitations. Lakegres implements the tried-and-tested server design techniques like non-blocking I/O, event queues, http 2/3 networking to maximize throughput and concurrency.
Open & Interoperable
Built on Hudi and Iceberg open table formats and ANSI-SQL for a zero lock-in architecture. Just point your existing Postgres clients to Lakegres to get going. Govern your data using your existing catalogs like AWS LakeFormation.
Production-Safe AI Architectures
Let AI agents run heavy, ad hoc queries without touching your operational databases. Replicate your operational data using OneFlow and Lakegres serves it directly behind a Postgres-compatible endpoint so exploration is fast, isolated, and safe for production.
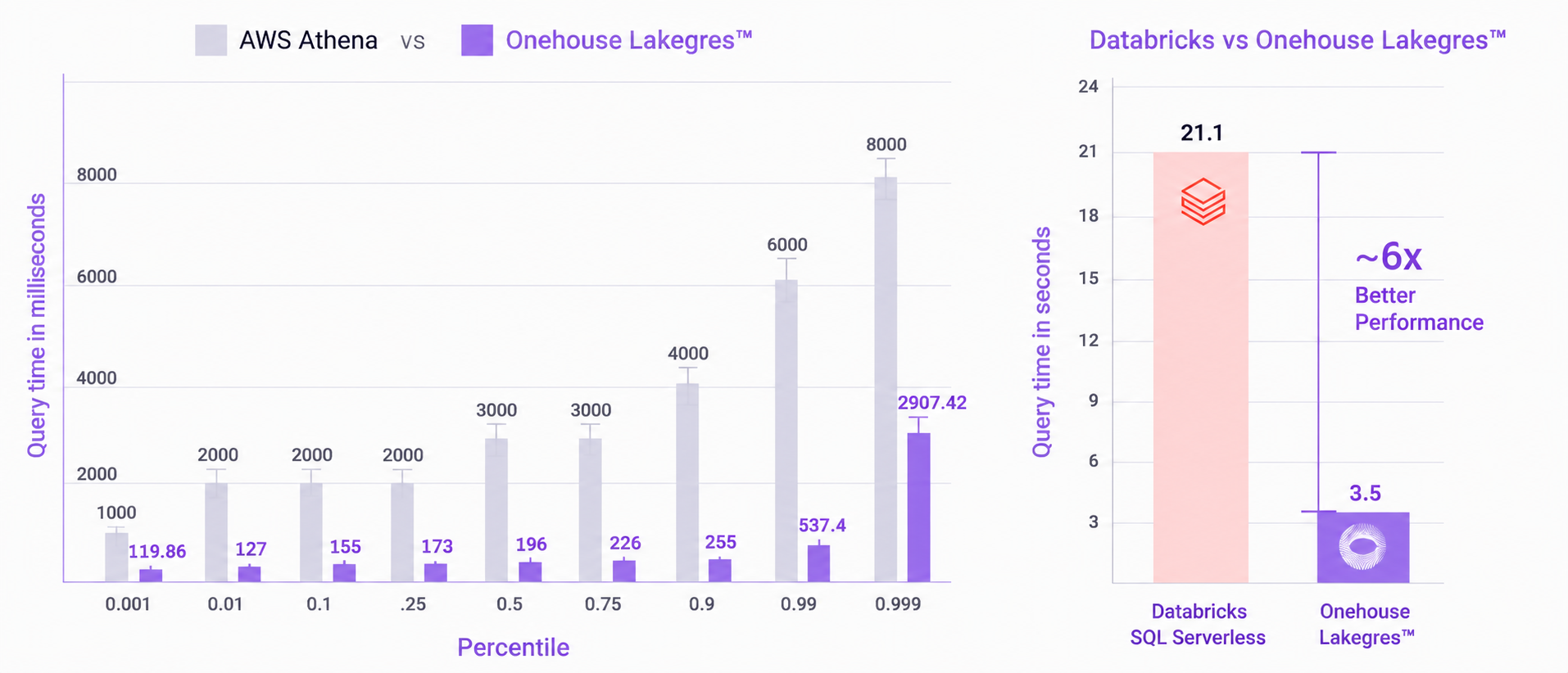
Database-Speed at Lakehouse Scale
- Intelligent indexing for point-lookups, ad hoc queries
- O(N) Index Joins to speed up data exploration 6x
- Columnar caching that avoids unnecessary compute overheads.
- Transactional caching that keeps queries always consistent with table commits.
- Vertical autoscaling based on query volumes
- Horizontal autoscaling to absorb unpredictable demand or spikes